
Enterprise AI Pilot Design: Building Evaluations That Support Defensible Decisions
A pilot that cannot produce a clear go or no-go decision is not a pilot, it is an extended demo. This guide covers how to scope, instrument, and time-bound an enterprise AI pilot so it produces evidence procurement can act on. Primary tag: AI Procurement

A pilot that cannot produce a clear go or no-go decision at the end of it is not a pilot. It is an extended demo, sometimes with a budget. The distinction matters because most enterprise AI pilots end without a defensible decision, which means the procurement that follows is shaped by sentiment, sunk cost, or board pressure rather than evidence. The vendor signed at the end of that procurement is not necessarily the wrong vendor. The procurement is just running blind.
A well-designed pilot is one of the highest-leverage activities in enterprise AI procurement. It is also one of the easiest to do badly, because the failure modes are subtle and the people running the pilot are usually the people most invested in its success. This article explores approaches to designing enterprise AI pilots that support more defensible decisions, why pilots often struggle to produce clear outcomes, and the patterns that can turn pilots into accidental deployments. It belongs inside the wider work of enterprise AI procurement before vendor evaluation.
What a Pilot Is For
A pilot is an evidence-gathering exercise. Its purpose is to test whether a specific solution, applied to a specific use case, produces a specific outcome that justifies a specific procurement decision. Each of those specifics matters.
A pilot is not for proving that AI is interesting. The reader has already decided AI is interesting, otherwise the pilot would not be funded. A pilot is also not for building enthusiasm. Enthusiasm is fine, but it is not evidence, and an enthusiastic pilot that produces no operational signal is worse than a small pilot that produces a clear answer.
A pilot is also not for selecting a vendor. Vendor selection typically happens before the pilot, on the basis of the procurement work covered in the enterprise AI vendor evaluation scorecard. The pilot tests the chosen vendor against a real use case. Running parallel pilots with multiple vendors is occasionally appropriate, usually expensive, and almost always confusing, because the comparison surfaces differences that are about pilot conditions rather than platform fit.
The output of a pilot is a decision document with a recommendation. Proceed to enterprise procurement, do not proceed, or proceed with conditions. If the pilot does not produce one of these three outputs cleanly, it has not done its job, regardless of how many people enjoyed using the tool.
Scoping the Pilot
Scope is often one of the biggest determinants of whether a pilot produces a useful decision. Most pilots are too broad. They test multiple use cases, across multiple teams, with several integrations, and arrive at the end with results that cannot be cleanly attributed to any single decision input. The right scope is narrow enough that the results mean something.
A well-scoped pilot covers one use case, one team, and the minimum integrations required to make the use case real. In practice, the use cases that produce the clearest pilot outcomes are ones that have already passed qualification through the use case definition work. If the use case has not been defined and tested against qualifying criteria, the pilot is testing an undefined thing, and undefined things produce undefined results.
The teams that tend to produce the most reliable pilot data are those that own the workflow being tested, rather than volunteer groups assembled from across the organisation. Volunteer groups produce optimistic adoption signals that do not survive contact with mandated rollout. A mix of capability levels within the pilot team also tends to produce more realistic adoption signals, because pilots run only with enthusiastic early users overstate the rollout case.
The integrations that matter most are the ones the use case actually depends on. If the production deployment will read from a customer relationship management platform and write to a ticketing system, the pilot that tests both produces a more reliable signal than one that simulates either. Pilots that simulate integrations using exports and manual imports do not test the integration, which means the integration risk is not retired by the pilot, which means it shows up at full scale during deployment.
A pilot scoped this way is small enough to manage, real enough to produce signal, and bounded enough to make a decision against.
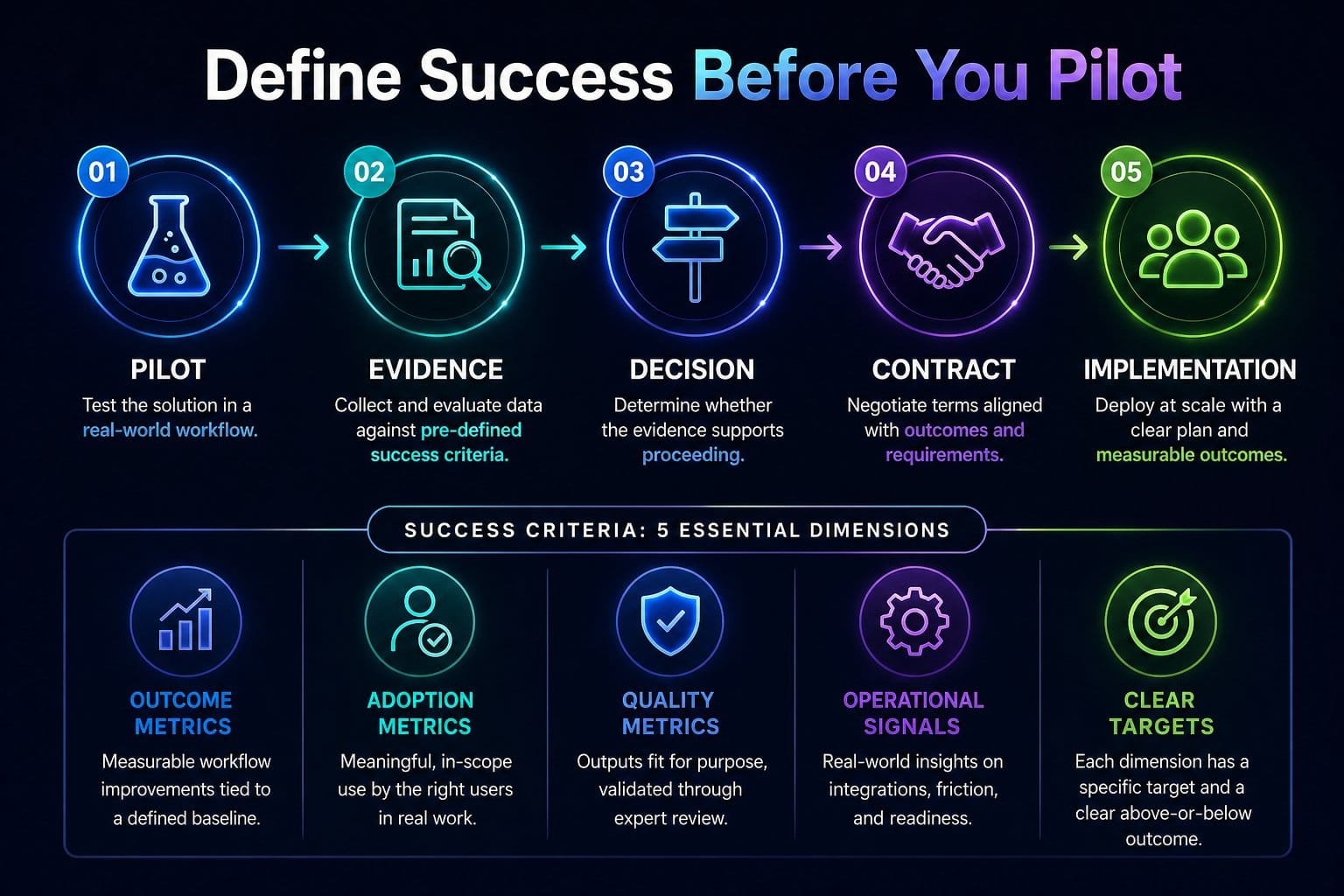
Defining Success Criteria Before the Pilot Starts
The single most common pilot failure is not having decided what success looks like before the pilot starts. The result is a pilot that finishes, produces some data, and then has its data interpreted against criteria that emerge during the interpretation. Whichever way the data points, someone can make it support the conclusion they wanted.
In pilots that produce defensible decisions, success criteria are typically defined upfront, written down, and agreed by the stakeholders whose approval the pilot is meant to inform. They tend to cover several dimensions, because a single-metric pilot rarely produces a defensible decision.
Outcome metrics. What measurable change in the workflow would justify proceeding. Reduction in handle time, improvement in accuracy, increase in throughput, reduction in error rate, change in user experience. In practice, these are most useful when tied to the baseline established during use case definition and set by the function that owns the workflow.
Adoption metrics. What level of voluntary use indicates the tool is fit for purpose. License activation is not adoption. Frequency of use, depth of use, and proportion of in-scope users actually using it for in-scope work are the adoption signals worth measuring. The how to measure enterprise AI adoption framing applies in pilot, not just at scale.
Quality metrics. What proportion of outputs are fit for purpose, and how is that being judged. Self-rated quality is unreliable. Sampled review by someone who knows the work is more useful, even though it is more effort.
Operational signal. What surfaced during the pilot that did not surface during the demo. Integration friction, governance gaps, support model limitations, latency issues, change management resistance. These are the signals that distinguish a vendor that demos well from a vendor that operates well, and they are the most valuable output of any pilot.
Each of these dimensions needs a target, and each target needs a clear above-or-below state. "Improved" is not a target. "Reduced from 12 minutes to 8 minutes per case" is. The pilot is then asking a question that has an answer rather than a question that has a debate.
Time-Bounding the Pilot
Pilots that do not have a defined end date do not end. They drift into informal deployments that are too embedded to switch off and too ill-formed to scale. For many enterprise pilots, a 30 to 90 day window is often sufficient to generate meaningful signal, and short enough that the pilot does not become its own dependency.
In well-structured pilots, the end date is agreed at the start, written into the pilot plan, and treated as a hard boundary. If at the end date the data is incomplete, in many cases, extending the pilot without changing the design simply extends the period of uncertainty. The answer is to make a decision against the data available, including the meta-decision that the data is insufficient and the pilot needs to be redesigned. Extending pilots that are not producing signal usually does not produce signal. It produces a pilot that has run for longer.
The end date is also when the decision document is produced. The document captures the success criteria, the data against each, the operational signals observed, the recommendation, and the conditions if any. The document is signed by the pilot owner and reviewed by the procurement and finance stakeholders who will act on it. Without the document, the pilot has not concluded, regardless of the calendar.
Instrumenting the Pilot
A pilot that is not instrumented does not produce data. It produces impressions. Impressions are sometimes correct and rarely defensible. In practice, the pilots that produce defensible decisions are the ones where instrumentation is in place before the pilot starts.
Usage instrumentation typically captures who used the tool, when, for what type of work, and at what frequency. Some enterprise AI platforms may be able to produce this telemetry. The question for the procurement team is whether that telemetry will be available, in a usable form, and accessible to the people analysing the pilot before it begins.
Quality instrumentation is more useful when designed deliberately. A small sampled-review process, run weekly during the pilot, produces a stable signal on output quality. Reviews are more reliable when done by someone who knows the work, against a written rubric, with results tracked over time. The rubric does not need to be elaborate. It does need to exist before the first review.
Operational instrumentation captures the friction signals that vendor demos do not show. A simple weekly debrief with the pilot users, with notes on what worked, what did not, and what was unexpected, produces this signal. Retaining the raw notes, rather than synthesising them away, tends to preserve diagnostic value, because the language users use to describe friction is itself informative.
Together, these three streams produce a pilot record that supports a defensible decision. Without them, the decision is being made on the strength of the loudest opinion in the room.
The Three Patterns That Turn Pilots Into Accidental Deployments
Pilots are vulnerable to drift. Three patterns recur, and each of them ends with a procurement decision that the pilot was not designed to support.
The expanding pilot. The original use case was narrow. During the pilot, users find new uses for the tool, the pilot scope quietly broadens, and by the end of the pilot the data covers a much wider set of activities than the original success criteria addressed. The decision document then has to choose between the agreed criteria and the broader usage data, and usually splits the difference, which is a way of saying it has no defensible position.
The unkillable pilot. The pilot ends, the data is mixed, and the decision is to extend or run a follow-on pilot. The tool stays in users' hands. Workflows quietly accumulate around it. By the time anyone tries to switch it off, the operational cost of doing so is high enough that the procurement decision is effectively made by inertia. This pattern is particularly common when the pilot vendor has set per-user pricing during the pilot and the contract auto-renews.
The pilot-as-rollout. The pilot was scoped narrowly, but the vendor and the internal sponsor have been treating the procurement as decided from the start. Implementation work happens during the pilot. Integrations are built. Champions are trained. By the time the success criteria are evaluated, the cost of not proceeding is greater than the cost of proceeding regardless of what the data says. This is the most expensive pattern, because it produces a procurement decision that is independent of the pilot evidence.
These patterns can often be reduced through deliberate pilot design. Hard scope boundaries that are policed during the pilot, not just at the start. Hard end dates with decision documents. A clear separation between pilot activity and implementation work. None of these are difficult. They do depend on someone owning them.
What Effective Decision Documents Typically Contain
A pilot decision document does not need to be long. It does need to be clear. In practice, the most useful decision documents tend to include:
- A statement of the use case tested, including its baseline and target.
- The success criteria as defined at the start of the pilot, with the data measured against each.
- The operational signals observed, organised by category (integration, adoption, governance, support).
- The recommendation: proceed, do not proceed, or proceed with conditions.
- If conditions, what they are and how they will be verified before enterprise commitment.
- If do not proceed, what the implications are: continue with current processes, run a different pilot, evaluate a different vendor, or close the use case.
This document feeds the enterprise AI business case, the contract negotiation, the implementation plan, and the change management plan. It is the artefact that travels with the procurement decision through every later stage. Its absence is felt later, when no one can quite remember why a particular vendor was chosen or what the pilot actually showed.
Sequencing and Common Mistakes
In many organisations, pilots sit between vendor selection and contract signature for enterprise commitment. It comes after the use case definition and the vendor evaluation, and before the multi-year contract. Pilots that run as the vendor evaluation tend to weight the vendor with the most polished pilot experience, which is not the same as the best vendor for the long-term use case. Pilots also tend to produce cleaner decisions when the budget is genuinely separate from the implementation budget. If the pilot is funded out of the implementation envelope, the implicit assumption is that implementation will follow, which weakens the go or no-go decision. The option to say no is the entire point.
Three further patterns recur. First, treating the pilot as a vendor relationship test. Vendors typically perform well during pilots because they are paying close attention, and the pilot relationship is rarely representative of the post-signature relationship. The reference check work is where the more reliable signal comes from. Second, confusing pilot success with deployment success. A pilot tests the use case under conditions that are smaller, more controlled, and more attended to than full deployment. Instrumentation that includes scaling questions tends to surface these gaps early: what would change at full scope, what governance issues would emerge at higher volume, what change management work would be needed across teams that did not pilot. Third, focusing only on outcome metrics and missing the friction observations that did not appear in the demo. Weekly user debriefs and integration friction notes are among the most valuable pilot outputs, and their absence is often felt when the decision document lacks operational depth.
A pilot run with discipline produces a decision the organisation can defend. A pilot run without discipline produces a procurement that proceeds for reasons no one can quite reconstruct. The difference is not effort. It is design.
This article provides general commercial and procurement commentary only and does not constitute legal, financial, or professional advice.