
Enterprise AI Spend Caps and Budget Controls: Token Limits, Rate Tiers, and Cost Containment Approaches
Enterprise AI spend can escalate quickly when consumption pricing, token usage, and platform controls are poorly governed. This article explains five layers of spend control, the cost levers procurement teams often miss, and how to reduce unexpected cost growth before contracts are signed.

The story is becoming familiar. A team builds a useful AI workflow, usage grows, and then something shifts: an agent calls another agent, a customer-facing integration sends more queries than expected, or a model upgrade quietly raises per-token costs. The next monthly invoice arrives with a number nobody approved, and no single decision that explains it. Finance escalates. Procurement is asked why the controls did not work. The honest answer, in many cases, is that the controls were never put in place.
Spend caps and budget controls are the operational mechanism that converts a consumption-priced contract into something finance can actually govern. In many well-governed deployments, they represent the difference between a controlled deployment and a deployment that is one configuration change away from a runaway invoice. Approaches vary by organisation, risk profile, and vendor capability. This article is written for procurement, finance, and IT leaders in Australian organisations navigating consumption-priced AI contracts. It covers where spend controls tend to operate, what procurement levers are available, and why addressing these before contract signature tends to produce better outcomes than deferring them to implementation. It belongs inside the broader enterprise AI pricing vs total cost of ownership framework, and it directly extends the cost-control discipline started in enterprise AI API pricing and token costs.
Why Caps Are Now a Procurement Concern
Under per-seat pricing, the budget control was the contract. Once signed, the spend was fixed. Procurement's job was to negotiate the price, and finance's job was to load the number into the budget. Neither function had to think about controlling spend during the term, because spend during the term was not variable.
Under consumption pricing, that is no longer true. Spend is variable, often substantially. The budget approved at signing is a forecast, not a ceiling. Without explicit ceilings configured at the platform layer, contractually, or through operational governance, organisations may have limited mechanisms for preventing unexpected spend growth. Depending on platform controls and commercial arrangements, usage may continue, charges may continue to accrue, and invoices may reflect actual consumption rather than forecast consumption.
This is typically treated as a procurement concern because the controls tend to be more effective when they are in place before contracts are signed. It is also a finance concern because the controls tend to be more effective when they are operational before deployment. And it is an operational concern because the controls are enforced day to day. Organisations that treat caps as a configuration task to be addressed during implementation often discover, after the first surprise invoice, that the configuration was never completed.
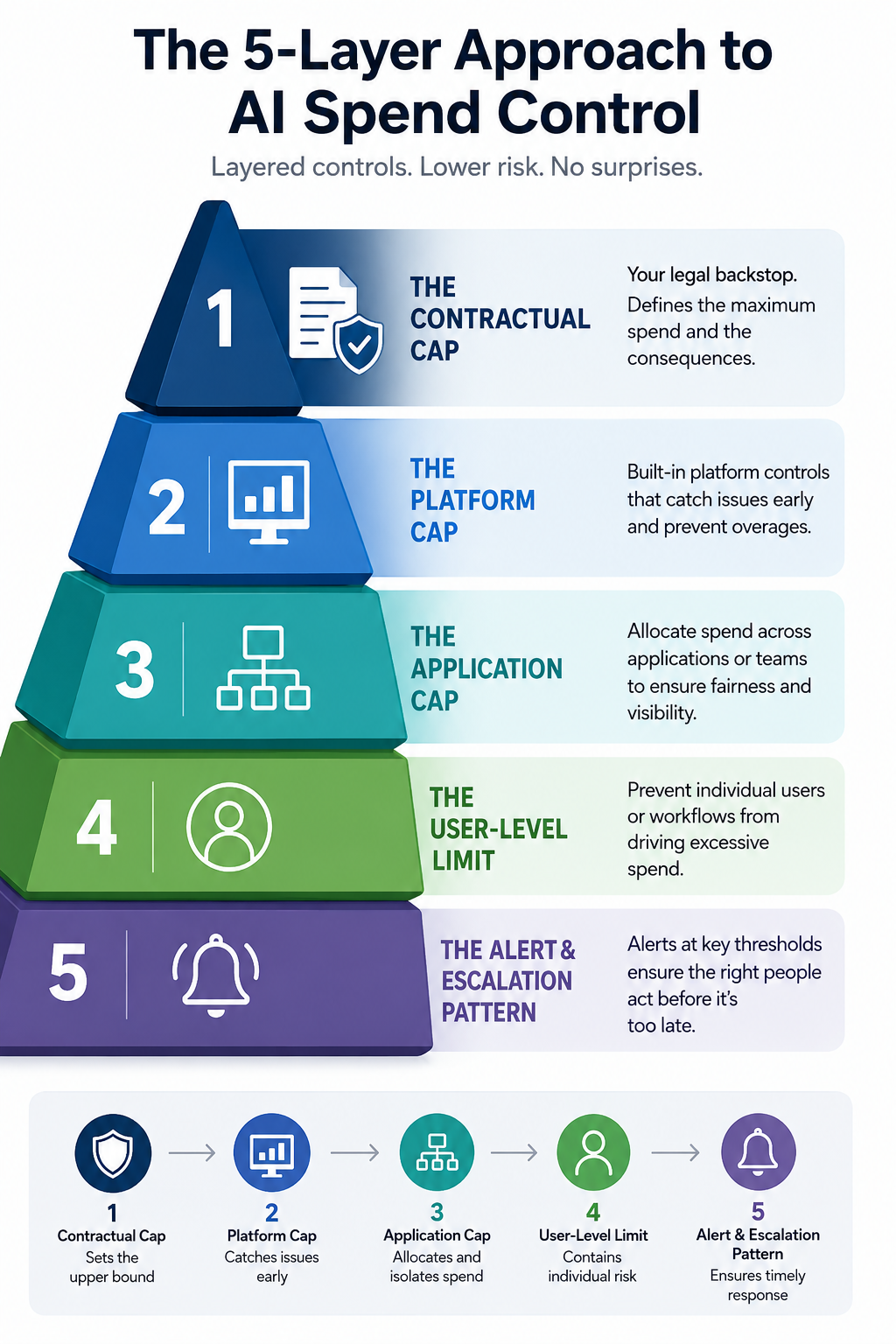
The Five Layers Where Caps Tend to Operate
A comprehensive control regime typically has caps operating at five distinct layers. Each layer catches different failure modes, and a control regime missing any of them can have a gap large enough to produce unexpected cost escalation.
Layer 1: The Contractual Cap
Organisations may wish to seek their own legal advice on the specific contractual provisions that achieve their commercial intent. The following observations are general in nature and are not a substitute for that advice.
Contracts in this space often define a maximum monthly or annual spend, with a stated consequence when the cap is reached. Some vendors throttle. Some block. Some continue to serve and bill at premium overage rates. The appropriate approach depends on the customer's risk profile and is typically worked through with legal counsel to confirm the drafting reflects the intended commercial outcome.
Contractual caps are often used as a commercial backstop because they may remain enforceable even where operational controls fail or are misconfigured. Amending contractual provisions will typically require agreement between the parties, subject to the terms of the agreement. For workloads where the financial risk of an overage is material, a contractual cap can serve as a backstop that makes other controls recoverable.
Vendors sometimes resist hard contractual caps because they create operational complexity. Procurement teams may reasonably respond that the absence of a cap creates corresponding complexity for the customer. The specific balance will depend on the negotiation and is typically reviewed with legal and finance stakeholders.
Layer 2: The Platform Cap
Many enterprise AI platforms support some form of administrative quota, budget control, or usage management capability, although capability depth varies materially between vendors. A monthly token budget. A daily query allowance. A hard quota on a particular model tier. These caps operate inside the vendor's platform and are enforced by the vendor's systems.
Platform caps tend to be the day-to-day operational control. They tend to catch the configuration errors and the unexpected usage spikes before they become invoice events. In many deployments, these are set lower than the contractual cap, with a buffer that gives the operations team time to respond if a cap is approached. Caps that are set at the same level as the contractual ceiling provide no operational margin.
Platform caps also tend to benefit from testing. A cap that has never been hit in testing is a cap that may not behave as expected when it is hit in production. Testing cap behaviour during pilot, rather than discovering it during the first surprise, is an approach some organisations find reduces operational risk.
Layer 3: The Application Cap
A single contract often serves multiple applications, teams, or use cases. Applying a single platform cap to the entire contract means unexpected usage growth in one application can consume the budget intended for several others. Application-level caps can prevent this by allocating spend allowances to each consumer of the platform.
This work is sometimes done with separate API keys, sometimes with platform-native organisational units, and sometimes with custom usage tracking layered on top of the vendor's telemetry. The mechanism matters less than the principle. Without application-level caps, cost attribution and cost containment are both operating at a level of granularity that may not support effective governance.
Layer 4: The User-Level Limit
Some failure modes occur at the individual user level. A misconfigured agent. A loop in a workflow. A user who has discovered they can trigger expensive reasoning queries from a chat interface. User-level controls, where supported, can help catch these failure modes earlier.
Not all platforms support user-level caps natively. Where they do not, the alternative is monitoring with alerts, which is generally more reactive than preventive. Either tends to be better than neither. The objective is typically to prevent any individual user, or any individual workflow, from driving material spend without the activity surfacing to someone responsible.
Layer 5: The Alert and Escalation Pattern
Caps that block traffic are a hard control. Alerts that warn of approaching thresholds are a soft control. A comprehensive regime typically has both. Alerts that fire at multiple thresholds tend to be the most operationally useful: a forecast threshold (spend is trending toward the cap), a percentage threshold (spend has reached 70 percent of the cap), and a near-cap threshold (spend has reached 90 percent of the cap). Each typically escalates to a defined owner with a defined response.
Alerts that fire to no one in particular tend to be decorative, not operational. The escalation pattern typically names a role and a response, not just a recipient. The cost of building the pattern is small. The cost of not having it is the time between an unexpected usage spike and someone noticing on an invoice three weeks later.
What the Vendor Typically Provides
Most of the layers above depend on platform capability the vendor either provides or does not. This capability is typically validated before signing in mature procurement processes, rather than assumed during implementation. The questions that tend to surface useful information include:
What native cap mechanisms the platform supports, at what levels (organisation, team, application, user), and on what time bases (daily, monthly, annual). What happens when a cap is hit: throttle, block, alert, or continue serving. What controls are exposed to customer administrators versus controlled only by the vendor. What usage telemetry is available to the customer in real time, and what is only available on monthly invoice. What rate limit tiers are available, how are they negotiated, and how are they enforced.
The answers form part of the enterprise AI vendor evaluation scorecard and the commercial terms that follow. Vague responses may indicate that caps could be left unenforced or weakly enforced, which is a procurement signal worth weighing.
The Three Cost-Control Levers Most Procurement Teams Miss
Beyond the cap structures themselves, three operational levers can materially change the cost profile of a deployment. They are routinely under-used, partly because vendor sales motions do not foreground them and partly because procurement does not always know they exist.
Model Routing
Most workflows do not need the most expensive model the vendor offers. A budget-tier model, a mid-tier model, and a premium reasoning model can each serve different parts of the same workflow. Routing queries to the cheapest model that is fit for the task is one of the highest-impact cost levers available, and it is a customer responsibility, not a vendor one. Vendors will typically continue to serve every query at premium rates if the customer's architecture sends every query to the premium model.
Routing logic that is designed as part of the architecture, rather than retrofitted after the first invoice, tends to produce better cost outcomes. The architecture choices covered in knowledge graph vs LLM vs RAG interact with routing decisions, and the combination tends to determine the realised cost profile.
Prompt and Context Caching
Some vendors offer discounted pricing or optimisation mechanisms for cached or repeated inputs, although implementation and pricing models vary significantly. Caching mechanisms vary by vendor, but the principle is consistent: repeated context may cost less than fresh context where vendor pricing models or caching mechanisms support it. Workflows that are designed without caching mechanisms may incur higher costs where repeated context is processed repeatedly. Workflows that are designed with caching in mind can reduce costs substantially on repetitive prompts and shared system contexts.
The procurement question is whether the vendor's caching mechanism is exposed to the customer, how it is priced, and whether the workflow architecture takes advantage of it.
Batch Processing and Asynchronous Modes
For workloads that do not require real-time responses, some vendors offer batch or asynchronous processing models that can provide lower unit costs for suitable workloads. The trade-off is latency. The use cases that tend to suit batch processing include overnight document processing, periodic data classification, and any workflow where a delay of minutes or hours is acceptable. Running these workloads through real-time interfaces means paying real-time rates for batch-acceptable work.
The questions that tend to clarify the opportunity are which of the customer's workloads are batch-suitable, what the rate differential is, and what the operational changes are to use batch modes. The savings can be material on the right workloads.
Operational Governance That Tends to Survive Contact With Reality
Caps and levers do not enforce themselves. They tend to work when supported by an operational governance pattern that reviews spend continuously, responds to alerts in defined ways, and adjusts caps as deployments evolve. The pattern that tends to work in practice has four elements.
A monthly cost review meeting where actual spend is compared to forecast, by application, with explanation for variance. In many organisations, this review is owned by a named role, not a committee, and it produces decisions, not just observations.
A defined response pattern for each alert threshold. Who investigates, who decides, who authorises a cap increase if one is needed. The response pattern is typically documented before the alerts fire, not improvised after they do.
A quarterly cap recalibration. As deployments mature, usage patterns shift. Caps that were appropriate in month one may be too restrictive in month six or too permissive in month nine. Recalibration tends to prevent both states from going unaddressed.
An annual contract review that feeds into the renewal preparation. The cost data from a year of operation is often the strongest input the customer has into the renewal conversation, and the controls that produced clean data are the controls that tend to produce a defensible negotiating position.
What Tends to Go Wrong When Caps Are Treated as Optional
The patterns that produce unplanned cost overruns are predictable, and they are almost always traceable to one or more missing layers in the regime above.
Workflows that worked at pilot scale can generate cost at production scale that no one modelled. Without a platform cap, the cost may simply be invoiced. Without an alert, the trend can be invisible until the invoice arrives. Without an application cap, the cost may be attributed to the wrong owner or to no one. Without a contractual cap, options for recourse may be limited.
Each missing layer creates a class of failure. Each layer in place can reduce exposure to a different class of failure. The regime does not need to be elaborate. It tends to work when it is complete.
Why This Tends to Belong in the Procurement Process
The temptation is to treat spend controls as an implementation task. The vendor is selected, the contract is signed, and operational controls are sorted out during deployment. By that point, the contractual cap is no longer negotiable, the platform capability is whatever it is, and the operational pattern is being built in response to invoice variance rather than in anticipation of it.
In many organisations, this work is addressed during procurement, before signing. Caps are often commercial provisions as much as operational details. Addressing these controls earlier tends to improve cost visibility and governance during deployment. The procurement team that defers them may find that actual cost depends on platform defaults that were never reviewed during the procurement process.
The cost of implementing these controls is often lower than the cost of addressing unexpected spend after deployment. The cost of explaining an unexpected cost overrun to finance, after the fact, with no controls to point at, tends to be considerably larger.
This article provides general commercial and procurement commentary only and does not constitute legal, financial, or professional advice.